
关于图片的收集方式
- 通过selenium脚本,打开浏览器,模拟操作下载一页的图片再翻页,如此循环
- 通过图片检索引擎的专用api,下载图片数据
- yahoo
- bing
- 百度
采集方式对比
| selenium | yahoo | bing | 百度 | ||
|---|---|---|---|---|---|
| 服务名称 | – | – | Bing Image Search API | Google Custom Search API | 待补充 |
| scraping or API | – | scraping | API | API | 待补充 |
| 是否需要用户登录 | 不需要 | 不需要 | 需要 | 需要 | 待补充 |
| API调用时是否需要key | 不要 | 不要 | API Key | API Key和自定义检索引擎ID | 待补充 |
| 免费计划 | 免费 | 免费 | 体验用户30天免费 | 每天100次查询免费,单次查询最多10枚图片 | 待补充 |
| 正常计费 | 免费 | 免费 | 1000次事务查询3美元,1次查询最多可获取150张图片 | 1000次查询5美元 | 待补充 |
| 1个关键字可取得图片数量 | 根据翻页结果 | 60枚 | 700~900枚左右 | 100枚 | 待补充 |
ps. 比较意外发现bing的接口比google的更具竞争力
想做的事情?
- 通过bing图片搜索接口收集大量的机器学习用图片素材
- 搜索关键字,图片数量,图片文件保存路径可配置化
- 图片文件名下载后统一整形成hash值加扩展名
开通Bing Search APIs体验计划
- 点击开通
-
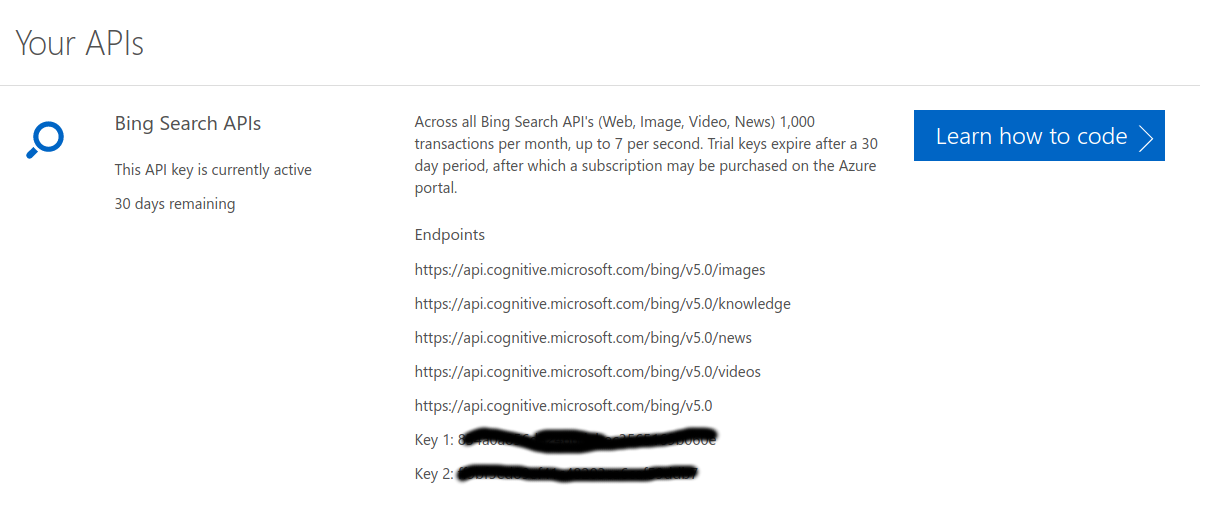
从网站获取API Key(Key1)。如下图所示
代码讲解
- 命令行参数定义
def argsCheck(parser):
parser.add_argument(
'--image_count',
type=int,
default=3,
help='collection number of image files per api call' # 定义单次查询图片返回数量
)
parser.add_argument(
'--off_set_start',
type=int,
default=0,
help='offset start' # 查询时偏移量,接续上次查询时需要。
)
parser.add_argument(
'--call_count',
type=int,
default=2,
help='number of api calls' # 接口循环次数
)
parser.add_argument(
'--output_path',
type=str,
default='~/sandbox',
help='image files output directory' # 定义图片保存路径
)
parser.add_argument(
'--query',
type=str,
default='cat',
help='search query' # 定义搜索关键字
)
- 下载图片功能
def download_image(url, timeout=10):
response = requests.get(url, allow_redirects=True, timeout=timeout)
if response.status_code != 200:
error = Exception("HTTP status: " + response.status)
raise error
content_type = response.headers["content-type"]
if 'image' not in content_type:
errror = Exception("Cotent-Type: " + content-type)
raise error
return response.content
- 创建文件夹及生成要保存图片文件的绝对路径
def make_img_path(save_dir_path, url):
"""Hash the image url and create the path
Args:
save_dir_path (str): Path to save image dir.
url (str): An url of image.
Returns:
Path of hashed image URL.
"""
save_img_path = os.path.join(save_dir_path, 'imgs')
make_dir(save_img_path)
file_extension = os.path.splitext(url)[-1]
if file_extension.lower() in ('.jpg', '.jpeg', '.gif', '.png', '.bmp'):
encoded_url = url.encode('utf-8')
hashed_url = hashlib.sha3_256(encoded_url).hexdigest().decode('utf-8') # 生成hash文件名
full_path = os.path.join(save_img_path, hashed_url + file_extension.lower())
make_correspondence_table(correspondence_table, url, hashed_url)
return full_path
else:
raise ValueError('Not applicable file extension')
- 图片请求主体
headers = {
'Content-Type': 'multipart/form-data',
'Ocp-Apim-Subscription-Key': bing_api_key, # API key (Key 1)
}
for offset in range(offset_count):
params = urllib.parse.urlencode({
'q': FLAGS.query, # 从命令行读取参数内容
'mkt': 'cn-zh',
'count': num_imgs_per_transaction,
'offset': offset * num_imgs_per_transaction + FLAGS.off_set_start,
'safeSearch': 'Moderate'
})
try:
conn = http.client.HTTPSConnection('api.cognitive.microsoft.com')
conn.request("GET", "/bing/v5.0/images/search?%s" % params, "{body}", headers) #注意是GET,用POST貌似不行,跟官方有些出入
response = conn.getresponse()
data = response.read() # 返回图片搜索接口数据
...
else:
decode_res = data.decode('utf-8')
data = json.loads(decode_res)
pattern = r"&r=(http.+)&p="
for values in data['value']:
unquoted_url = urllib.parse.unquote(values['contentUrl'])
img_url = re.search(pattern, unquoted_url)
if img_url:
url_list.append(img_url.group(1)) # 提取图片url
for url in url_list:
try:
img_path = make_img_path(save_dir_path, url)
image = download_image(url) # 下载图片
save_images(img_path, image, url) # 保存图片文件到指定文件夹
完整代码
运行程序
- 修改
authentication.ini文件中的bing_api_key的值 - 运行脚本
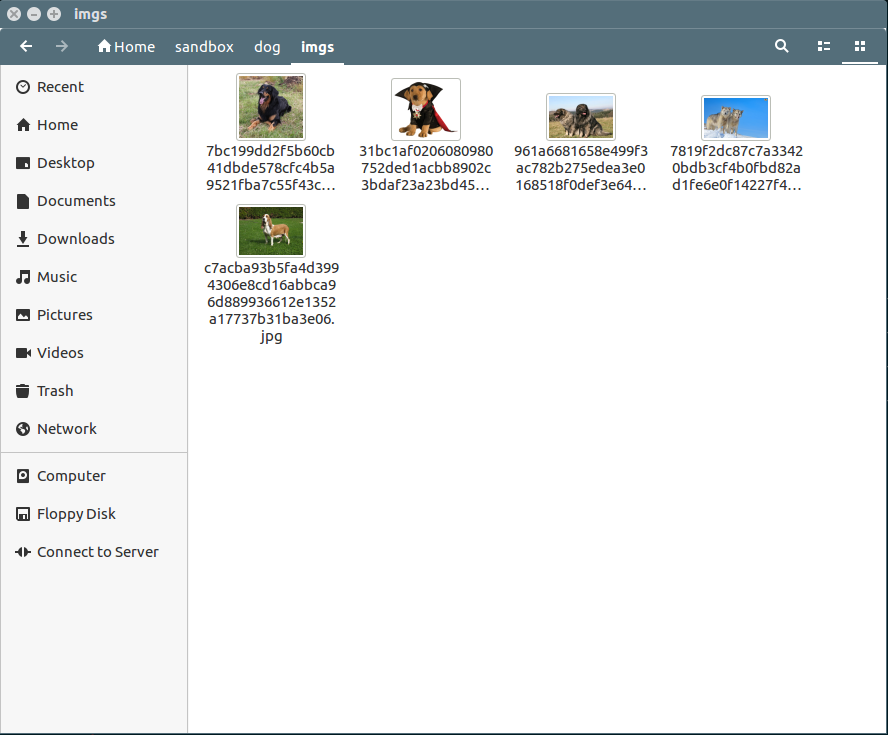
python3 image_collector.py --output_path "/home/***/sandbox/dog" --query "dog" --image_count 5 --call_count 4
运行结果
存在的问题
- 接口请求多次,返回结果有重复图片链接,导致图片数量小于请求预期总数
参考链接
https://qiita.com/ysdyt/items/49e99416079546b65dfc
http://qiita.com/ysdyt/items/565a0bf3228e12a2c503